
Motivation
In a modern business environment, managing communication efficiently is crucial. Email remains a vital medium for various types of communication, including inquiries, support requests, and transactional updates. However, categorizing and processing a large volume of emails manually is not only time-consuming but also prone to errors. Automating this process can lead to significant improvements in efficiency and accuracy.
Use Case
Our client uses SAP Solution Manager as central helpdesk and ticketing system. Since every IT problem is handled with a ticket, more than 100 tickets are created per day. Each ticket belongs to a certain category, with more than 350 categories to choose from. E-Mails to the central helpdesk address are created as unclassified tickets and manually classified as the next step. It is obvious that an automation of the ticket classification process can save hundreds of working hours and, thus, Euros per year.
Approach
To address this challenge, we aim to develop and deploy an AI model capable of automatically categorizing incoming emails based on their content. By leveraging machine learning, specifically Natural Language Processing (NLP), the model can learn from historical data and predict the correct category for new emails. This automation allows for faster response times and more streamlined workflows, ultimately enhancing the overall productivity of the team.
Workflow
The core of this project is the development of a machine learning model trained on a dataset of previously categorized emails. The model is designed to predict the correct category for new incoming emails, allowing for automatic sorting and routing to the appropriate department or workflow.
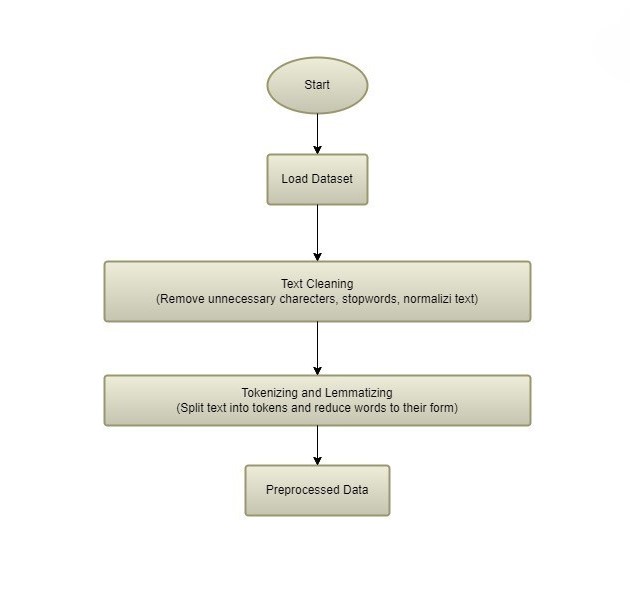
Preprocessing Data
To train the model, we started by gathering a large dataset of emails that had already been categorized by experts. This dataset was then cleaned and preprocessed to ensure the model could learn effectively. The preprocessing steps included:
- Text Cleaning: Removing unnecessary characters, stopwords, and normalizing the text to ensure consistency.
- Vectorization: Converting the email content into numerical features using techniques such as TF-IDF (Term Frequency-Inverse Document Frequency) to represent the importance of terms relative to the dataset.
- Handling Imbalanced Data: Utilizing techniques like SMOTE (Synthetic Minority Over-sampling Technique) to balance the categories in the training data, ensuring the model does not favor more common categories over rarer ones.
Model Selection
For this project, we selected Logistic Regression as the machine learning model to classify the emails into predefined categories. Logistic Regression is a well-established, interpretable model that performs particularly well for binary and multi-class classification tasks. Its ability to output probabilities for class predictions allows for a clear understanding of the model’s confidence in its predictions, making it a reliable choice for this type of classification problem.
Why Use Logistic Regression?
- Simplicity and Interpretability: Logistic Regression is simple to implement and interpret. The model’s coefficients provide insights into how each feature impacts the prediction, which can be particularly useful for understanding which words or phrases are most indicative of certain categories.
- Performance: Despite its simplicity, Logistic Regression often performs competitively with more complex models, especially when the features are well-prepared, as they are with the TF-IDF vectorization used in this project.
- Handling Imbalanced Data: Logistic Regression can be configured to handle imbalanced datasets through the use of class weights. In this project, we utilized the
class_weight='balanced'option, ensuring that the model paid equal attention to all categories, regardless of their frequency in the dataset.
Training the Model
After preprocessing the data and vectorizing the text, the next step was to train the Logistic Regression model. Given the potential for imbalanced data, we first addressed this by applying SMOTE (Synthetic Minority Over-sampling Technique) or RandomOverSampler depending on the specific characteristics of the training data.
- SMOTE was applied when the dataset had enough samples per category, allowing the generation of synthetic examples for minority classes.
- RandomOverSampler was used as a fallback when any category had too few examples for SMOTE to function correctly.

The model was then trained using the resampled data to ensure balanced learning across all categories. We also set the maximum number of iterations (max_iter=1000) to give the model sufficient time to converge, particularly given the size and complexity of the dataset.
Evaluation
After training, the model was evaluated using a separate test set. The performance was measured through metrics such as precision, recall, and F1-score, which are particularly useful for understanding the model’s effectiveness in the context of imbalanced data.
The trained model showed promising results in accurately categorizing emails across the different predefined categories. The detailed classification report highlighted the model’s strengths and identified areas for potential improvement.
Save the Model
To facilitate easy deployment and future use, the trained Logistic Regression model, along with the TF-IDF vectorizer, was saved using joblib. This allows for quick loading and application of the model on new, unseen data without the need for retraining.
Results
After evaluating the model on the test data, we achieved an accuracy of 88%, meaning that the model correctly categorized 88% of incoming emails. However, it’s important to note that the remaining 18% were not entirely incorrect. In some cases, the model predicted a more general category than the specific one originally assigned by human operators. This indicates that while the prediction might not have matched the exact category, it still provided a valid classification that could be considered relevant for broader purposes. This flexibility suggests that the system can still save time and effort in many cases by offering general, yet useful, categorization. With these results, the model is already highly suitable for practical use and can be seamlessly integrated into the client’s workflow.
Next Steps
Moving forward, we plan to make this model available as an internal service that can be easily accessed by other teams within the organization. The AI-based ticket classification can be integrated into the existing SAP Solution Manager or any similar helpdesk systems, allowing for automated, scalable, and accurate ticket categorization. By transforming this solution into a centralized service, it can be reused across multiple departments, enhancing the overall efficiency of the ticketing process.
In the future, we aim to further improve the model by expanding the training data, ensuring it becomes even more accurate and reliable over time. As more tickets are processed and categorized, we will continue to add new categories and refine existing ones. This will allow the system to handle a broader range of inquiries, including rare cases.
Are you interested in our classification system or need support for your own AI endeavors? Please don’t hesitate to get in touch. We look forward to tackling new challenges in the field of AI.